参考自LeetCode上Explore模块的Binary Tree,作为笔记记录。
Overview 综述
树可以视为包含N个节点和N-1条边的有向无环图。
二叉树是每个节点最多有两个子树的树结构,子树称为左子树和右子树。
Traverse A Tree 树的遍历
主要内容:
- 理解和区分树的遍历方法
- 能够运用
递归方法解决树的为前序遍历、中序遍历和后序遍历问题 - 能用运用
迭代方法解决树的为前序遍历、中序遍历和后序遍历问题 - 能用运用
广度优先搜索解决树的层序遍历问题
树的遍历介绍
前中后序主要是看根节点什么时候访问。
前序遍历(Pre-order Traversal)
前序遍历首先访问根节点,然后遍历左子树,最后遍历右子树。
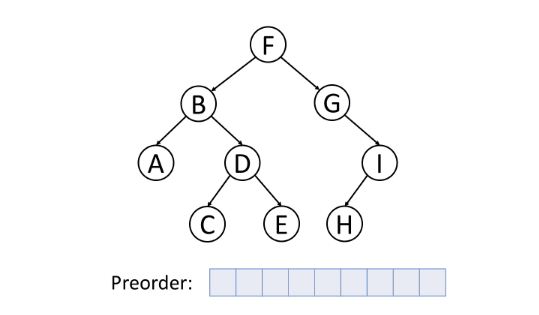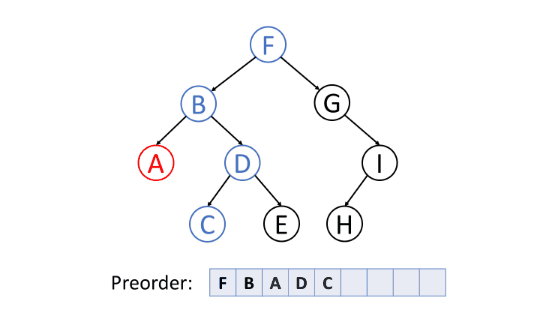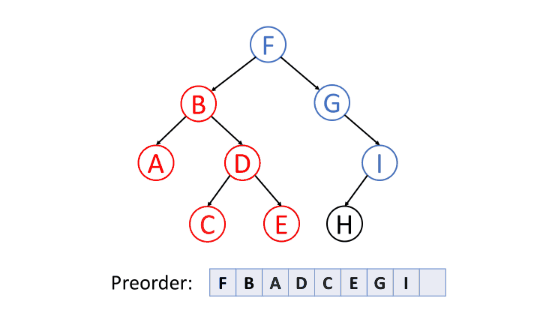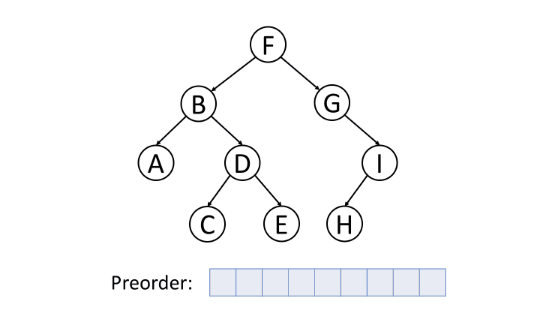
中序遍历(In-order Traversal)
中序遍历首先遍历左子树,然后访问根节点,最后遍历右子树。
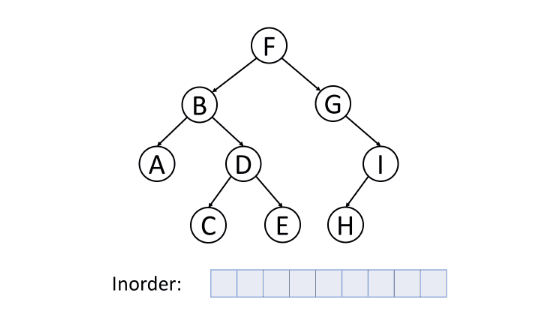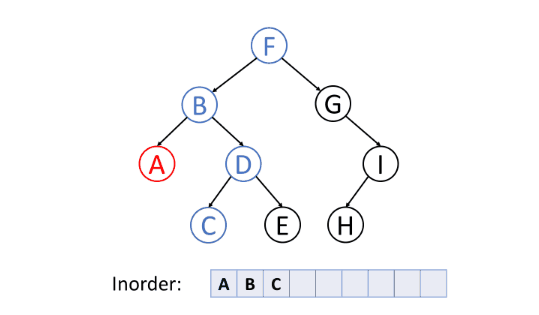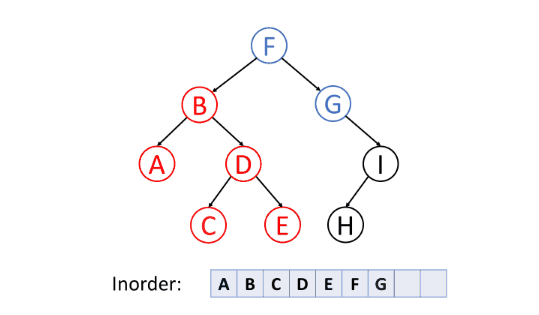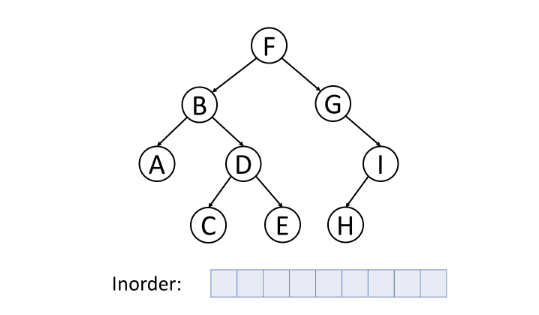
一般,对于二叉搜索树,可以通过中序遍历得到一个递增的有序序列。
后序遍历(Post-order Traversal)
后序遍历首先遍历左子树,然后遍历右子树,最后访问根节点。
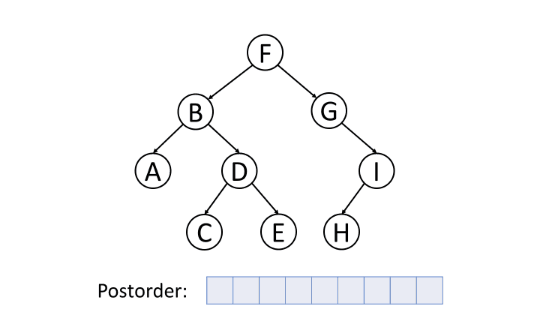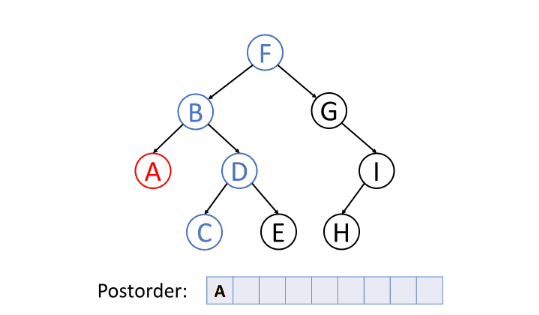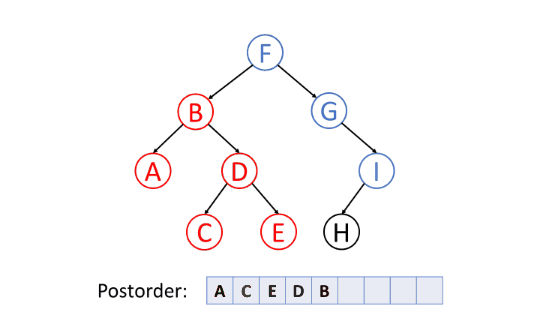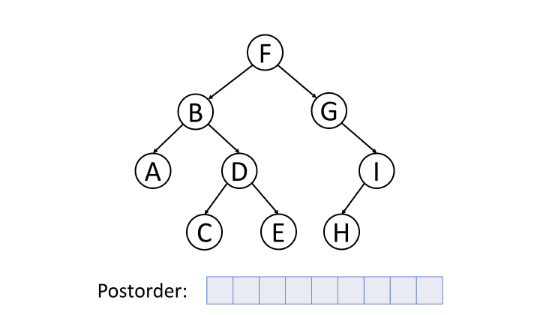
删除树中的节点的时候,删除过程将按照后序遍历的顺序进行。即,删除一个节点时,将首先删除其左节点和右节点,然后再删除节点本身。
数学表达式中,可以用中序遍历找出原始表达式,但是解析处理的时候,使用后序遍历更容易,每遇到一个操作符就从栈中弹出栈顶的两个元素进行计算,将计算结果返回栈中。
递归和迭代实现树的遍历
递归:程序返回一个函数,这个函数继续返回一个函数,直至达到最初的递归终止条件,然后一步步返回,最终得到结果;
迭代:在给定条件下直接循环计算,从小到大直至返回最终结果;
前序遍历
给定一个二叉树,返回它的 前序 遍历。
示例:
1 | 输入: [1,null,2,3] |
递归实现:
1 | /** |
迭代实现:
前序遍历先访问根节点,之后访问左子树和右子树。
对于任一节点,可以看做是根节点直接访问,访问结束后,如果左子树非空,则同样规则访问左子树,到达最左后,再访问右子树。
- 从根节点开始遍历,同时输出根节点;
- 递归输出直至最左;
- 到达最左后,访问右节点;
因此处理过程如下:
对于任一节点P:
- 访问节点P,并将节点P入栈;
- 判断节点P的左子树是否为空,为空则取栈顶节点,并进行出栈操作,并将栈顶节点的右孩子置为当前的节点P,循环至1;若不为空,则将P的左孩子置为当前的节点P;
- 直至P为NULL且栈为空,则遍历结束;
1 | /** |
中序遍历
给定一个二叉树,返回它的中序 遍历。
示例:
1 | 输入: [1,null,2,3] |
递归实现:
1 | /** |
迭代实现:
中序遍历先访问左子树,再访问根节点和右子树。
对于任一节点,优先访问左节点,左节点可视为又一根节点,继续访问其左子树,直至到最左节点,之后按相同规则访问右子树。
- 从根节点开始遍历;
- 递归直至最左,然后输出(中序遍历首先输出的是最左叶子节点);
- 到达最左后,访问右节点。
处理过程如下:
对于任一节点P:
- 若左子树不空,则将P入栈并将P的左孩子置为当前节点P,再对当前节点P进行相同处理;
- 若左子树为空,则取栈顶元素并进行出栈操作,访问栈顶节点,并将当前节点P置为栈顶节点的右孩子;
- 直至P为NULL或栈为空则结束遍历。
1 | /** |
后序遍历
给定一个二叉树,返回它的 后序 遍历。
示例:
1 | 输入: [1,null,2,3] |
递归实现:
1 | /** |
迭代实现:
后序遍历是先访问左子树和右子树,最后访问根节点。
后序遍历比前序和中序要相对复杂,因为要保证左子树和右子树都已经被访问,并且左子树在右子树之前被访问,之后才能访问根节点。
所以按照之前前序和中序的思路,在流程控制上需要做一定调整。
处理过程如下:
- 对于任一节点P,将其入栈,并沿左子树遍历到最左节点,此时该节点在栈顶,但不能出栈访问,因为还没有访问右子树。
- 按照相同规则访问右子树,当访问完右子树后,这个节点又出现在栈顶,此时可以将其出栈并访问,从而保证正确的访问顺序。
- 由上可知,每个节点会两次出现在栈顶,只有第二次出现在栈顶的时候才可以访问并出栈,因此需要多设置一个变量来标识节点是否第一次出现在栈顶。
1 | /** |
层序遍历
层序遍历就是逐层遍历树结构。
使用广度优先搜索遍历树时,就是按照层序遍历顺序进行的:从一个根节点开始,首先访问节点本身,之后遍历其相邻节点,其次遍历其二级邻节点、三级邻节点,以此类推。
过程如下图所示:
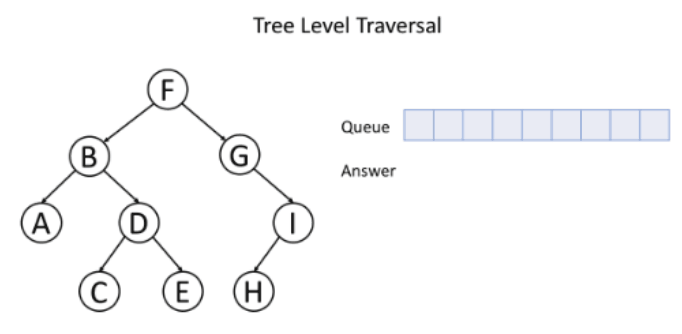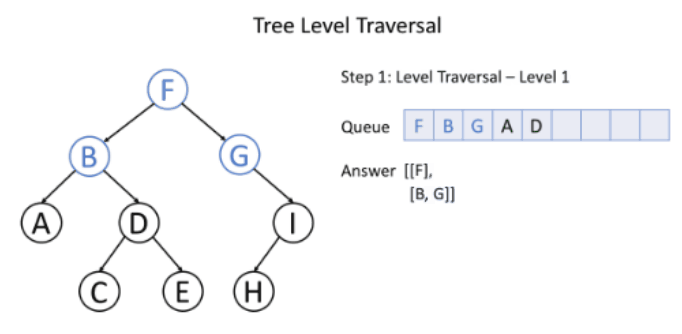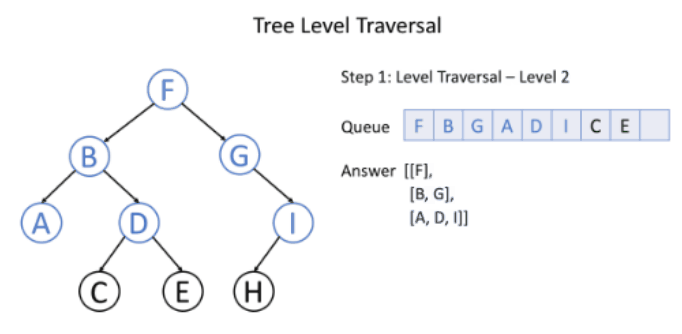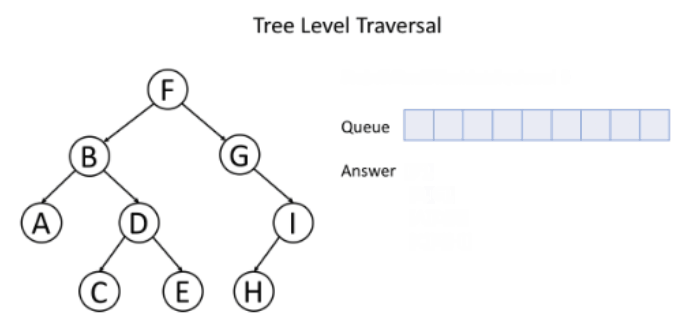
实现
给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。
例如:
给定二叉树: [3,9,20,null,null,15,7],
1 | 3 |
返回其层次遍历结果:
1 | [ |
使用队列来辅助实现。用队列记录当前一层的节点,从根节点开始。每次遍历完一层时,先计算队列中的元素数量size,用size控制之后要处理的节点数量(因为每次处理一个节点的时候,会将其左右子节点压入队列,所以队列中会加入下一层的节点,所以需要通过size来控制当前层要处理的节点数量)。所有节点处理结束后,队列为空,则遍历结束。
代码如下:
1 | /** |
Solve Problems Recursively 运用递归解决问题
主要内容:
介绍两种典型的递归方法,练习使用基础的递归方法解决二叉树相关问题。
运用递归解决树的问题
递归是树的特性之一,许多树的问题可以通过递归的方式来解决。
自顶向下的解决方案
自顶向下可以认为是一种前序遍历,在每个递归层级,先访问节点进行计算,然后递归调用的时候将值传递到子节点。
原理如下:
- return specific value for null node
- update the answer if needed // anwer <— params
- left_ans = top_down(root.left, left_params) // left_params <— root.val, params
- right_ans = top_down(root.right, right_params) // right_params <— root.val, params
- return the answer if needed // answer <— left_ans, right_ans
例如,给定二叉树,寻找其最大深度。
用递归函数maximun_depth(root, depth)自顶向下解决该问题,每向下一层深度就加1,最终比较所有叶子节点处的最大深度即可,伪代码如下:
return if root is null
if root is a leaf node:
answer = max(answer, depth) // update the answer if needed
maximum_depth(root.left, depth + 1) // call the function recursively for left child
maximum_depth(root.right, depth + 1) // call the function recursively for right child
如图所示:
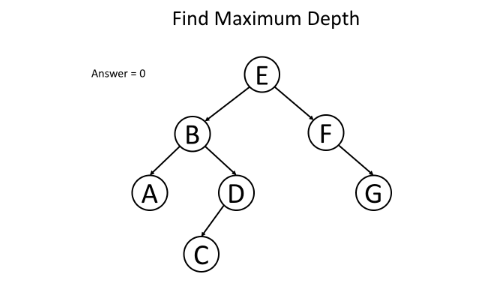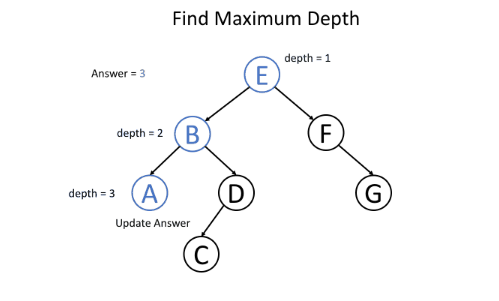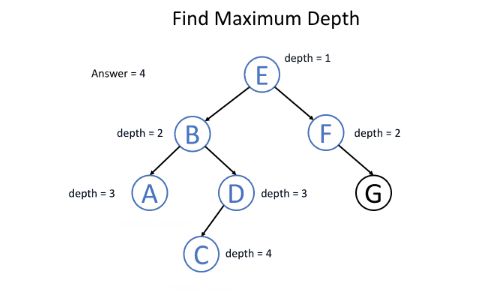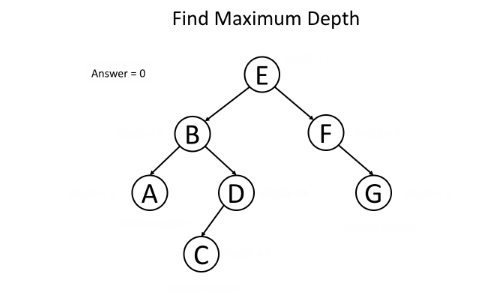
代码如下:
1 | int answer; // don't forget to initialize answer before call maximum_depth |
自底向上的解决方案
自底向上可以看过是后序遍历的一种,在每个递归层次上,首先对所有子节点做递归调用,然后根据返回值和根节点本身的值得到最终答案。
原理如下:
- return specific value for null node
- left_ans = bottom_up(root.left) // call function recursively for left child
- right_ans = bottom_up(root.right) // call function recursively for right child
- return answers
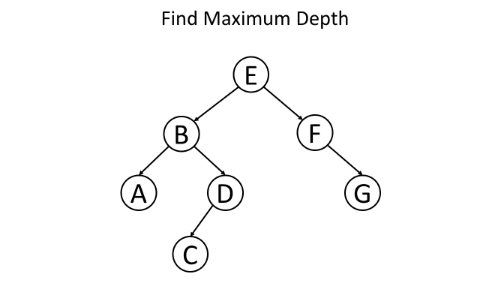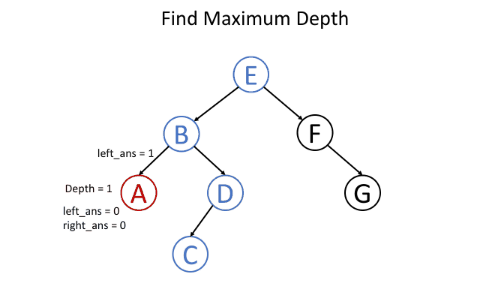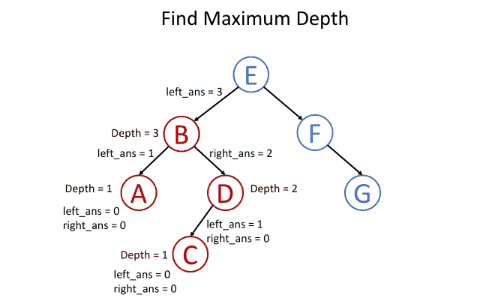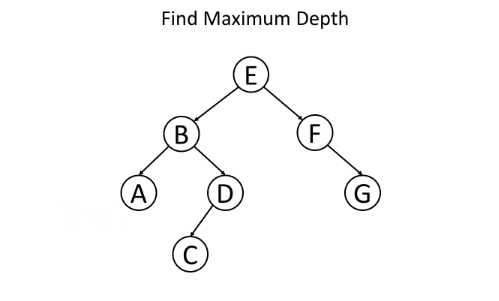
同样以二叉树最大深度为例。
用递归函数maximun_depth(root)自底向上的解决该问题,对于树的某个节点,比较其左节点和右节点的最大深度,再加1即可,也就是对于每个节点,都可以在解决其子节点问题之后得到答案,伪代码如下:
- return 0 if root is null // return 0 for null node
- left_depth = maximum_depth(root.left)
- right_depth = maximum_depth(root.right)
- return max(left_depth, right_depth) + 1 // return depth of the subtree rooted at root
如图所示:
代码如下:
1 | int maximum_depth(TreeNode* root) { |
总结
当遇到树问题时,请先思考一下两个问题:
- 你能确定一些参数,从该节点自身解决出发寻找答案吗?
- 你可以使用这些参数和节点本身的值来决定什么应该是传递给它子节点的参数吗?
如果答案都是肯定的,那么请尝试使用 “自顶向下” 的递归来解决此问题。
或者你可以这样思考:对于树中的任意一个节点,如果你知道它子节点的答案,你能计算出该节点的答案吗? 如果答案是肯定的,那么 “自底向上” 的递归可能是一个不错的解决方法。
练习:二叉树最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
返回它的最大深度 3 。
代码如下(自底向上递归实现):
1 | /** |
练习:对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 | 1 |
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 | 1 |
说明:
如果你可以运用递归和迭代两种方法解决这个问题,会很加分。
官方给出的两种题解思路
递归方法
如果一个树的左右子树互为镜像,则这棵树是对称的。
当两棵树满足如下条件时,互为镜像:
- 两个根节点有相同的值;
- 每棵树的左子树都和另一棵树的右子树镜像对称;
1 | /** |
迭代方法
用队列进行迭代,队列中每两个相邻的值应该是相等的,且其子树也互为镜像。队列由两个连续的root节点开始。每次提取两个节点进行比较,然后把两个节点的左右子节点按相反顺序插入队列。队列为空,或检测到不对称时,算法结束。
1 | /** |
练习:路径综合
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
1 | 5 |
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
代码如下:
1 | /** |
总结
多练习就对了,,,
练习:从中序与后序遍历序列构造二叉树
【LeetCode】106
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
1 | 中序遍历 inorder = [9,3,15,20,7] |
返回如下的二叉树:
1 | 3 |
解题思路
中序遍历结果为左中右,后序遍历结果为左右中,题目假设树中没有重复元素,则可以先用后序遍历结果的尾值确定当前根节点P,在中序遍历中找到当前根节点P(假设位置为$n$),并将其分为左右两个子树(根节点P左侧为左孩子,右侧为右孩子,两个子树为$inorder[:n] , inorder[n+1:]$)。根据这个划分位置$n$,再将后序遍历序列也分隔成两部分(两部分为$postorder[:n] , postorder[n:-1]$),之后递归构造左右子树。
代码如下:
1 | /** |
练习:从前序与中序遍历序列构造二叉树
【LeetCode】105
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
1 | 前序遍历 preorder = [3,9,20,15,7] |
返回如下的二叉树:
1 | 3 |
解题思路
前序遍历结果为中左右,中序遍历结果为左中右,可以按照前面中序和后序构造二叉树的方法进行。
首先取前序遍历结果的首值作为当前根节点P,并在中序遍历结果中找到当前根节点P的位置$n$,并以此为依据,将中序遍历序列划分为左右两个子树$inorder[:n] , inorder[n+1:]$。同时根据这个位置$n$,再将前序遍历序列也划分为两部分$preorder[1:n+1] , preorder[n+1:]$。
代码如下:
1 | /** |
练习:填充每个节点的下一个右侧节点指针
【LeetCode】116
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
1 | struct Node { |
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:
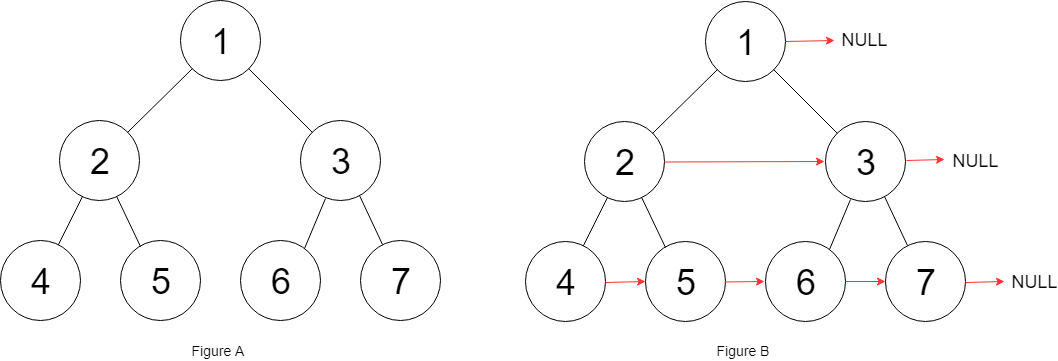
1 | 输入:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":null,"right":null,"val":4},"next":null,"right":{"$id":"4","left":null,"next":null,"right":null,"val":5},"val":2},"next":null,"right":{"$id":"5","left":{"$id":"6","left":null,"next":null,"right":null,"val":6},"next":null,"right":{"$id":"7","left":null,"next":null,"right":null,"val":7},"val":3},"val":1} |
提示:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
解题思路
按照题意思路直接遍历即可。
代码如下:
1 | /* |
练习:填充每个节点的下一个右侧节点指针 II
【LeetCode】117
给定一个二叉树
1 | struct Node { |
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:
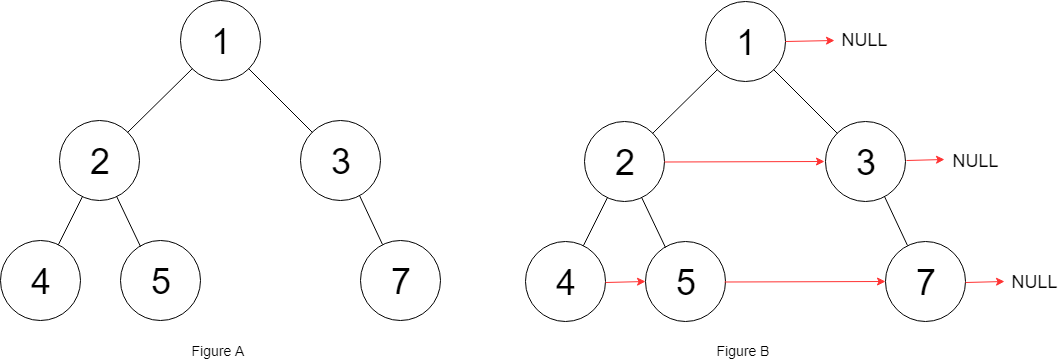
1 | 输入:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":null,"right":null,"val":4},"next":null,"right":{"$id":"4","left":null,"next":null,"right":null,"val":5},"val":2},"next":null,"right":{"$id":"5","left":null,"next":null,"right":{"$id":"6","left":null,"next":null,"right":null,"val":7},"val":3},"val":1} |
提示:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
代码如下,详见注释:
1 | /* |
小结:填充每个节点的下一个右侧节点指针问题
1、调试环境
对于上述两道填充右侧节点指针的题目,LeetCode上没有给出调试环境,在网上看到有相关的内容,记录如下:
1 |
|
2、通用解法
可以利用之前层序遍历的思路,维护一个树节点队列queue(先进先出),记录本层剩余的节点数和下一层的节点数。
上述两个问题均可用该方法解决。
具体过程:
- 初始将根节点插入到队列中,每次从队列中取一个节点;
- 判断该节点是否有左右子节点,若有则加入到队列中,并将下一层节点数加一;
- 从队列中弹出该节点,将本层剩余节点数减一;
- 若本层还有剩余节点,说明该节点有同层的兄弟节点,则将其next指针指向队首节点;
- 若剩余节点数为0,则说明本层遍历结束,将剩余节点数置为下一层的节点数,并将下一层的节点数置为0;
按照上述过程遍历,直至队列为空,则可完成树中所有next指针指向同层兄弟节点的操作。
代码如下:
1 | /* |
练习:二叉树的最近公共祖先
【LeetCode】236
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
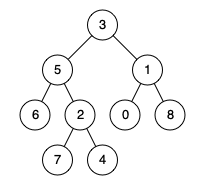
示例 1:
1 | 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 |
示例 2:
1 | 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 |
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
解题思路
按前序遍历的思路,从根节点开始遍历左右子树,直到找到第一个在左右子树中找到目标节点的节点。若该子树不包含目标节点,则返回NULL。
具体过程:
- 先判断当前节点是否是目标节点,是则返回该节点(空节点则返回NULL);
- 递归在左右子树中查找最近公共祖先节点;
- 若在左右子树都找到目标节点,则说明目标节点刚好分布在当前节点的左右两侧,则返回当前节点;
- 若左右子树只有一侧找到目标节点,则返回找到的那个节点,对应题目中一个节点是其本身的祖先的情况;(有一侧返回NULL说明目标节点都在另一侧,题目明确目标节点都存在于树中,所以另一侧初次找到其中一个目标节点的地方就是最近公共祖先,另一个节点必然在该节点的子树中)
- 若两侧都未找到,则返回NULL;
代码如下:
1 | /** |
练习:二叉树的序列化与反序列化
【LeetCode】297
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例:
1 | 你可以将以下二叉树: |
提示: 这与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
说明: 不要使用类的成员 / 全局 / 静态变量来存储状态,你的序列化和反序列化算法应该是无状态的。
解题思路
按先序遍历的思路,将二叉树进行序列化,空节点用“#”保存(以确保节点插入到正确的位置)。为反序列化过程读取节点值方便,节点值之间用空格隔开。反序列化时,仍然按照先序遍历的思路即可。
序列化过程:
- 如果当前节点为空,则str += “# “;
- 递归进行先序遍历,并记录节点值;
- str += root->val + “ “
- serialize(root->left, str)
- serialize(root->right, str)
反序列化过程:
- 读取字符串中一个节点值;
- 如果该值是数字,则以该值构建当前根节点 root = new TreeNode(val);
- 递归构建左右子树;
- 如果该值不是数字,则 root = NULL,返回;
代码如下:
1 | /** |
实际在LeetCode解题时,题目说明代码验证方式是
codec.deserialize(codec.serialize(root));,只验证最后deserialize的返回值,并没有验证serialize的值(题目说序列化方法不限,所以也没法验证这个序列化结果的正确性的感觉),所以就意味着验证过程的返回值必然和输入值一样。参考代码如下(Java):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>
> // Encodes a tree to a single string.
> TreeNode root;
> public String serialize(TreeNode root) {
> this.root = root;
> return null;
> }
>
> // Decodes your encoded data to tree.
> public TreeNode deserialize(String data) {
> return root;
> }
> }
>